
You can create a new dataset source in NVivo, by importing data from:
A Microsoft Excel spreadsheet (.xlsx or .xls)
A text file containing comma or tab-separated values (.txt)
A database—for example, a Microsoft Access or SQL Server database.
What do you want to do?
You cannot add additional records (rows) or fields (columns) to a dataset after import, so it is important to gather your data before you start the import operation.
For each dataset that you want to create, your data must be gathered into one of the following:
Microsoft Excel worksheet
Tab or comma delimited text file
Database table or view
You cannot select multiple worksheets, text files or database tables when you import data to create a new dataset.
The maximum amount of data that can be imported into a single dataset is 256 fields (columns) and 1,048,576 records (rows).
NOTE Text files must be organized as a tab or comma-delimited field values, so that the Dataset Import Wizard can divide the contents into records (rows) and fields (columns). Each record must be on a separate line, and each field must be separated by the delimiter. The following is an example of a comma-delimited text file:
You cannot change the analysis type (codable or classifying) of a field (column) after import, so you should decide how you want to use your data before you create a new dataset.
Fields that contain data that you intend to code and analyze should be stored as codable fields—for example, responses to open-ended survey questions, such as How do you think we can reduce our carbon emissions?
Fields that describe your data (metadata) should be stored as classifying fields—for example, the ID number, Age, Sex and Annual Income of your survey respondents. Values in classifying fields:
Can be used to sort and filter the records in your dataset.
Provide context when you view coded dataset content in a node.
Can be used to build node structures that group your codable content—for example, by Age or Sex.
Can be used to create and classify nodes that represent the subjects (cases) of your research. For example, if you create a 'person' node for a survey respondent, you can use the classifying field values Age or Sex as attribute values on the node.
When you choose to store a field as a classifying field, you may be able to choose from several possible data types—for example, date or text. You cannot change the data type of a classifying field after import, so it is important to choose a data type that supports sorting, filtering and grouping the field values. For example, if the field contains dates, and you want to filter by date ranges, you should store the values as a date (not as text).
If you want to create nodes that represent the subjects (cases) in your research—you will need a unique identifier for each subject in your data. If your data does not contain a unique identifier that you can use as a node name, you could add a unique ID number for each subject. This identifier should be imported as a classifying field.
Open the file that contains your data in a text editor or Microsoft Excel:
Text files should be opened in a text editor, such as Notepad.
Spreadsheets should be opened in a spreadsheet application, such as Microsoft Excel.
If you are importing data from Excel, ensure that the data is gathered into a single worksheet.
For both text files and Excel spreadsheets, review your data as described below:
| Element | Description |
| Blank rows | Remove any blank rows within the data. |
| Extraneous content | Your file should contain only the rows you want to import, and (optionally) a 1st row containing field labels. Any other content should be removed. |
| Data types | Make sure every value in a field contains the same type of data. During the import operation, NVivo scans the first 25 rows of your file to determine what data types are appropriate for each field. If you choose to import a field using the date, time, date/time, boolean, integer or decimal data types, all the rows in your text file must contain valid data for that data type. If a row after the 25th line, contains invalid data, the import operation will terminate with errors. For more information about the values that can be store in a particular data type, refer to Valid data types. |
If you are importing a text file, review your data as described below:
| Element | Description |
| Records | Each record must be on a separate line. Remove any blank lines at the beginning or end of the file. |
| Field delimiters | Make sure that the file consistently uses tabs or commas to separate field values. |
| Text qualifiers | Some delimited text files contain field values enclosed in single or double quotation marks, for example:
The single or double quotation mark that encloses the field value is a text qualifier. Field values must be enclosed within text qualifiers when the field delimiter (comma or tab) appears within field values. For example, if comma is the field delimiter, and Dallas, Texas is a valid field value, you must enclose the value within qualifier, like this: "Dallas, Texas" During the import operation, you can specify whether the file uses a text qualifier, and whether the qualifier is the single or double quotation mark. |
If you are importing data in an Excel Spreadsheet, review your data as described below:
| Element | Description |
| Merged cells | Merged cells can cause errors during the import operation. We recommend that you do not import spreadsheets containing merged cells. |
| Calculated values | If a cell displays a calculated value, the displayed value (not the formula) is imported into the dataset. |
| Error values | If any of the cells in your worksheet display error values such as #NUM or #DIV, you should correct them before you start the import operation. Columns containing error values can only be imported as text fields—refer to Valid data types for more information. |
| Buttons and checkboxes | If any cells contain controls such as buttons or checkboxes the spreadsheet cannot be imported. You should remove these controls before import. |
Close the text file or spreadsheet. Keeping the file open may cause errors during the import operation.
Ensure that the data you want to import is gathered into a single table or view—you may need assistance from your database administrator to do this.
Review your data as described below:
| Element | Description | |||
| Data types | The following OLE DB data types are supported: | |||
| BigInt | DBTime | LongVarWChar | UnsignedSmallInt | |
| Binary | DBTimeStamp | Numeric |
UnsignedTinyInt |
|
|
Boolean |
Decimal | Single | VarChar | |
|
BSTR |
Double | SmallInt | VarNumeric | |
|
Char |
Guid |
TinyInt | VarWChar | |
| Date | Integer | UnsignedBigInt | WChar | |
|
DBDate |
LongVarChar |
UnsignedInt | ||
|
Binary objects |
Databases can store 'binary objects' such as images, documents, audio or video files. If you import fields containing binary objects, any image, document or media files in supported formats (except plain text files) will be imported into NVivo as separate sources. The dataset contains 'source shortcuts'—you can access the source by clicking on the shortcut. Refer to About datasets for more information. If you intend to import a large number of audio or video files, you should consider where you want to store your media files—refer to Store audio and video files for more information. |
|||
NVivo provides a 'wizard' that guides you through the import process. The wizard examines the data you are importing and helps you to ensure that the data is imported the way that you want.
To create a new dataset:
On the External Data tab, in the Import group, click Dataset.
The Import Dataset Wizard opens.
Click the Browse button, and then locate and select the text file or Excel spreadsheet that contains the data you want to import.
Spreadsheets can contain multiple worksheets—select the worksheet that contains the data you want to import.
Check the Data Preview to make sure you have selected the right worksheet.
File Encoding Select the file encoding that is used in the text file. NVivo tries to detect the file encoding used in the file—if the Data Preview area is blank or displays strange characters, try a different file encoding.
Field Delimiter Select the character that separates the values in your text file (tab or comma).
Text Qualifier Select the character (single or double quotation marks) that encloses text values in your text file. All text enclosed within text qualifiers is imported as one value, even if the text contains a delimiter character. For example, if the delimiter is a comma (,) and the text qualifier is a double quotation mark ("), "Dallas, Texas" is imported as one field value. If no text qualifier is selected, it is imported as two separate values.
Check the Data Preview to make sure your data is being interpreted correctly.
Under Dates, Times and Numbers, you can specify the format of any dates, times and numbers in your data. By default, NVivo expects that your data uses the dates, time and number formats specified in your Windows Regional Settings (Windows Control Panel).
Date Order Select the order of day, month and year in your dates—for example, if your file contains the date 10/05/2005 and you select MDY, NVivo interprets the date as 'October 05, 2005'. If you select DMY, NVivo interprets the same date as 'May 10, 2005'. When the data is imported into NVivo, it will be displayed in the date format that is specified in your Windows Regional Settings (Windows Control Panel).
Date Delimiter If the days, months and years in your dates are separated by a delimiter character (for example a slash (/) or a dash (-), enter the delimiter. If days, months and years are not separated by a delimiter, clear this box.
Time Delimiter If the hours, minutes and seconds in your times are separated by a delimiter character (for example, a colon (:), enter the delimiter. If the hours, minutes and seconds are not separated by a delimiter, clear this box.
4 Digit Years Select this option, if the years in your dates include the century—for example '1999' or '2010'. If the years in your dates do not include the century, clear this box.
Leading Zeroes in Dates Select this option if the days and months in your dates include leading zeroes—for example, January is represented by '01'. If your dates do not have leading zeroes, clear this box.
Decimal Symbol Specify the decimal separator that is used in your numbers. When the data is imported into NVivo, it will be displayed with the decimal separator that is specified for your country/region in your Windows Regional Settings (Windows Control Panel).
First row contains column headings Select this option when the first row of your spreadsheet contains the names of your columns.
The Data Preview shows the values in the first 25 rows.
On this screen you can choose which fields contain values that you want to code (codable fields) and which fields contain values that describe your data (classifying fields).
By default, all fields (columns) are imported, and the analysis type (codable or classifying) is preselected based on the content in the first 25 rows of the data.
Field Selection You can use the buttons in this box to select or deselect all fields for import. For example, if you want to import only a few fields from a spreadsheet with many columns, you can deselect all fields, and then individually select the fields you want to import.
Under Field Options, you can check or change the default options for the field (column) that is currently selected in the Data Preview box at the bottom of the dialog box. The currently selected column is highlighted—you can select another column by clicking on a column header.
Field Name This option displays the field name that will be used in the new dataset. If the first row of your data does not contain column headings, the field names are set to Column A, Column B, Column C etc. You can change these field names.
Import Field Select this check box to import the field. If you clear this check box, the field is not imported.
Under Analysis Type, you can choose:
Codable Field Select this option if the field contains text you want to analyze—for example, responses to open-ended survey questions. The Data type is preselected—you cannot change this setting.
Classifying Field Select this option if the values in the selected field describe the data—for example, the ID number, Sex or Age of survey respondents. You cannot code content in classifying fields to nodes. The Data type is preselected, based on the values in the first 25 rows. If more than one data type can be used to store the values in the column, you can change the data type—refer to Valid data types for more information about data types. The Decimal Places box is available when the decimal data type is selected—if you reduce the number of decimal places, the data will be truncated.
The Data Preview shows the values in the first 25 rows and indicates how each field will be imported. Use the scroll bars to move left and right as you review the field options selected for each column. In the example below, three of the four columns will be imported:
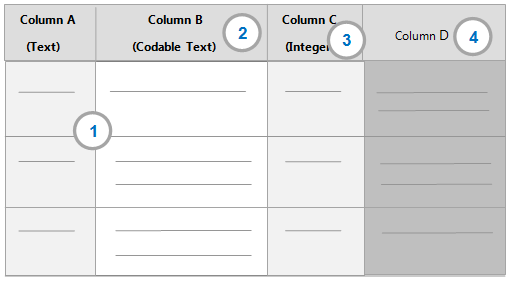
1 The background color of the columns indicate how they will be imported:
White—imported as a codable field
Light grey—imported as a classifying field
Dark grey—not imported
2 This is a codable field—the data type is shown in brackets (you cannot change the data type for a codable field).
3 This is a classifying field—the selected data type is shown in brackets below the column name. You can change the data type if you think another type is more suitable.
4 The dark grey background indicates that you are not importing this field.
Enter a name and description for your new dataset.
In this step, you will establish a connection to your data source. This topic explains how to:
Connect to a Microsoft Access database
Connect to a SQL Server database
Connect to any ODBC-compliant data source using a data source name (DSN). Consult your network administrator, if you need help with setting up a DSN on your computer. Connecting via a DSN can be convenient, if you regularly import data from the same database.
If you have difficulty establishing a connection, consult your network or database administrator.
To connect to a Microsoft Access database:
Click Browse, and then select files of type ODBC. The Data Link Properties dialog box opens.
On the Provider tab, select Microsoft Office 12.0 Access Database Engine OLE DB Provider, and then press Next.
On the Connection tab, under Enter the data source and/or location of the data, in the Data Source box, enter the file path and file name of the Access database you want to connect to. For example, 'C:\myfiles\mydatabase.accdb'.
If the Access database is password-protected, enter your User name and Password, and select the Allow saving password check box.
Click Test Connection, to check that you can connect to the database.
Click OK.
To connect to a SQL Server database:
Click Browse, and then select files of type ODBC. The Data Link Properties dialog box opens.
On the Provider tab, select Microsoft OLE DB Provider for SQL Server, and then press Next.
On the Connection tab, under Select or enter a server name, enter the SQL server name and instance (e.g. 'myserver\instancename'), or click the arrow beside the box to select from the list of SQL server instances that are defined on your network.
Under Enter information to log on to the server, select your authentication method. You can select:
Use Windows NT Integrated security Select this option, to use your current Windows user name and password to login to the SQL server.
Use a specific user name and password Select this option, to use your SQL user name and password to login to the SQL server. If you select this option, you must enter your User name and Password, and select the Allow saving password check box.
Under Select the database on the server, enter the name of the database or click the arrow beside the box to select from the list of databases on that server.
Click Test Connection, to check that you can connect to the database.
Click OK.
To connect any ODBC-compliant data source using a data source name (DSN):
Click Browse, and then select files of type ODBC. The Data Link Properties dialog box opens.
On the Provider tab, select Microsoft OLE DB Provider for ODBC drivers, and then press Next.
On the Connection tab, under Use data source name, enter a data source name (DSN) that has been mapped on your computer by your network administrator, or click the arrow to select from the list of all the DSNs that are mapped on your computer.
Depending on the DSN configuration, you may need to enter a user name and password. If required, under Enter information to log on to the server, enter your User name and Password, and check the Allow saving password check box.
Click Test Connection, to check that you can connect to the database.
Click OK.
Select the table or view that you want to import the data from.
On this screen you can choose which fields contain values that you want to code (codable fields) and which fields contain values that describe your data (classifying fields).
By default, all fields (columns) are imported, and the analysis type (codable or classifying) is preselected based on the content in the first 25 rows of the data.
Field Selection You can use the buttons in this box to select or deselect all fields for import. For example, if you want to import only a few fields from a spreadsheet with many columns, you can deselect all fields, and then individually select the fields you want to import.
Under Field Options, you can check or change the default options for the field (column) that is currently selected in the Data Preview box at the bottom of the dialog box. The currently selected column is highlighted—you can select another column by clicking on a column header.
Field Name This option displays the field name that will be used in the new dataset. If the first row of your data does not contain column headings, the field names are set to Column A, Column B, Column C etc. You can change these field names.
Import Field Select this check box to import the field. If you clear this check box, the field is not imported.
Under Analysis Type, you can choose:
Codable Field Select this option if the field contains text you want to analyze—for example, responses to open-ended survey questions. The Data type is preselected—you cannot change this setting.
Classifying Field Select this option if the values in the selected field describe the data—for example, the ID number, Sex or Age of survey respondents. You cannot code content in classifying fields to nodes. The Data type is preselected, based on the values in the first 25 rows. If more than one data type can be used to store the values in the column, you can change the data type—refer to Valid data types for more information about data types. The Decimal Places box is available when the decimal data type is selected—if you reduce the number of decimal places, the data will be truncated.
The Data Preview shows the values in the first 25 rows and indicates how each field will be imported. Use the scroll bars to move left and right as you review the field options selected for each column. In the example below, three of the four columns will be imported:
1 The background color of the columns indicate how they will be imported:
White—imported as a codable field
Light grey—imported as a classifying field
Dark grey—not imported
2 This is a codable field—the data type is shown in brackets (you cannot change the data type for a codable field).
3 This is a classifying field—the selected data type is shown in brackets below the column name. You can change the data type if you think another type is more suitable.
4 The dark grey background indicates that you are not importing this field.
Enter a name and description for your new dataset.